Pencil Puzzle Benchmark
A Benchmark for Multi-Step Verifiable Reasoning

Today we're releasing Pencil Puzzle Bench, a benchmark for evaluating LLM reasoning on pencil puzzles — constraint-satisfaction problems with deterministic, step-level verification.
From a dataset of 62,231 puzzles across 94 types, we curate a benchmark subset of 300 puzzles spanning 20 puzzle types, and evaluate 51 models from 11 providers in two settings: single-shot solving and agentic multi-turn solving with verifier feedback.
The headline result: the best model we tested (GPT-5.2 at maximum reasoning effort) reaches 56.0% in agentic mode — and roughly half the benchmark remains unsolved.
- Play the Puzzles: ppbench.com
- Paper: Paper (arXiv)
- Dataset + runs: Hugging Face
TL;DR
- Verifiable reasoning benchmark: every intermediate board state is checked by a deterministic rules engine (no LLM-as-judge).
- Big dataset, curated benchmark: 62k puzzles → 300-puzzle benchmark across 20 types.
- Two evaluation modes: direct (single-shot) vs agentic (multi-turn with verifier feedback).
- Strong scaling signals: inference-time compute and agentic iteration both matter.
- Still hard: best score is 56%; ~50% remains unsolved.
Why pencil puzzles?
Pencil puzzles are a sweet spot for evaluating reasoning:
- pure constraints (no subjective grading)
- long multi-step deduction chains
- wide coverage (dozens of puzzle families, each with different structure)
- low contamination risk (communities share puzzles to be solved, not answer keys)
Sudoku is one example. Pencil Puzzle Bench includes a broader set: Nurikabe, Slitherlink, Masyu, Yajilin, Light Up, and more.
The key differentiator: step-level verification
Most benchmarks only evaluate whether the final answer is right.
Pencil Puzzle Bench evaluates whether the reasoning process stays valid.
Every move updates a board state, and every state can be checked with a deterministic verifier that returns specific, localized error messages (which rule was violated, and where on the board).
This gives you:
- unambiguous scoring
- dense training signals for process supervision
- an environment that naturally supports tool-using agents and RL from verifiers
What we released
Pencil Puzzle Bench includes:
- A benchmark split (300 puzzles across 20 types, with multiple difficulty tiers)
- A full dataset (62,231 puzzles across 94 types)
- An evaluation harness with two strategies
- A Gym-compatible environment for agent/RL-style work
Evaluation setup
Strategy 1: Direct ask (single-shot)
The model receives a puzzle and must output a complete solution as a JSON move list.
- One inference call
- Evaluated on all 300 benchmark puzzles
Strategy 2: Agentic (multi-turn + verification)
The model interacts with tools (make_move, make_multi_move, check_board_for_completeness, render_board_as_svg, get_rules, reset_puzzle, give_up) to iteratively propose moves, check constraints, and course-correct based on deterministic feedback.
- Evaluated on a shared 30-puzzle subset for all models
- Expanded to 84 puzzles for top models
We intentionally keep these as simple baselines — the goal is to measure where models are, not to maximize scores with heavy prompt engineering.
Results
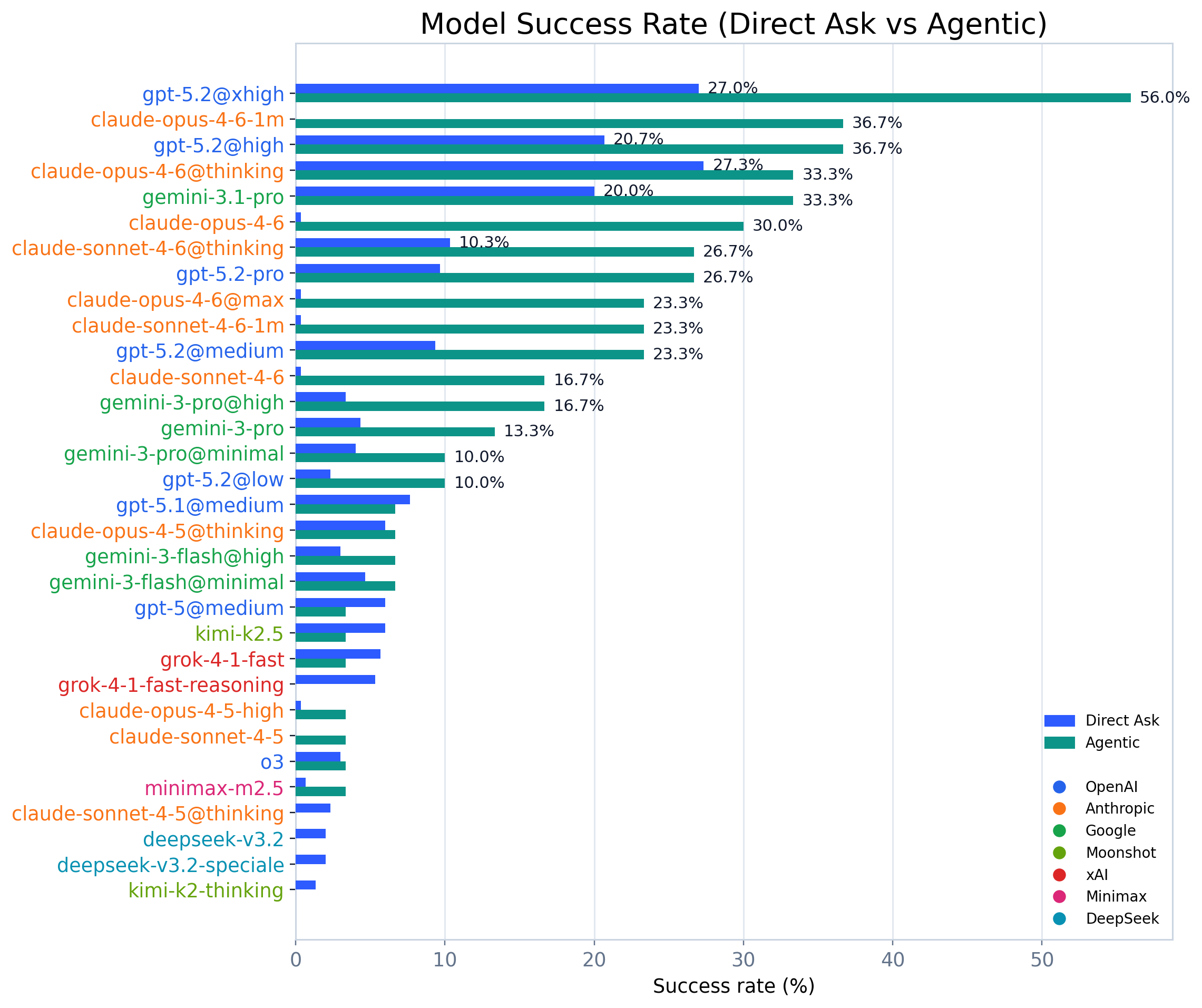
Leaderboard snapshot
Representative results (direct-ask on 300 puzzles; agentic on model-specific subsets): - GPT-5.2@xhigh: 27.0% direct-ask, 56.0% agentic (84 puzzles) - Claude Opus 4.6@thinking: 27.3% direct-ask, 33.3% agentic (84 puzzles) - Claude Opus 4.6 (no extended thinking): 0.3% direct-ask, 30.0% agentic (30-puzzle baseline) - Gemini 3.1 Pro: 20.0% direct-ask, 33.3% agentic (84 puzzles)
On matched puzzles (same puzzles, both modes), the agentic gain is +30.0pp for Claude Opus 4.6 and +35.7pp for GPT-5.2@xhigh.
The high-level story: reasoning depth (internal chain-of-thought, controlled by effort level) and agentic iteration (external trial-and-error with verifier feedback) are two distinct axes of capability. Claude Opus 4.6 without extended thinking has near-zero direct-ask performance but reaches 30.0% through iteration alone; GPT-5.2@xhigh is already strong single-shot but still gains +35.7pp from agentic mode. The strongest systems combine both.
Reasoning effort scaling
One of the cleanest signals in the benchmark is how much inference-time compute matters.
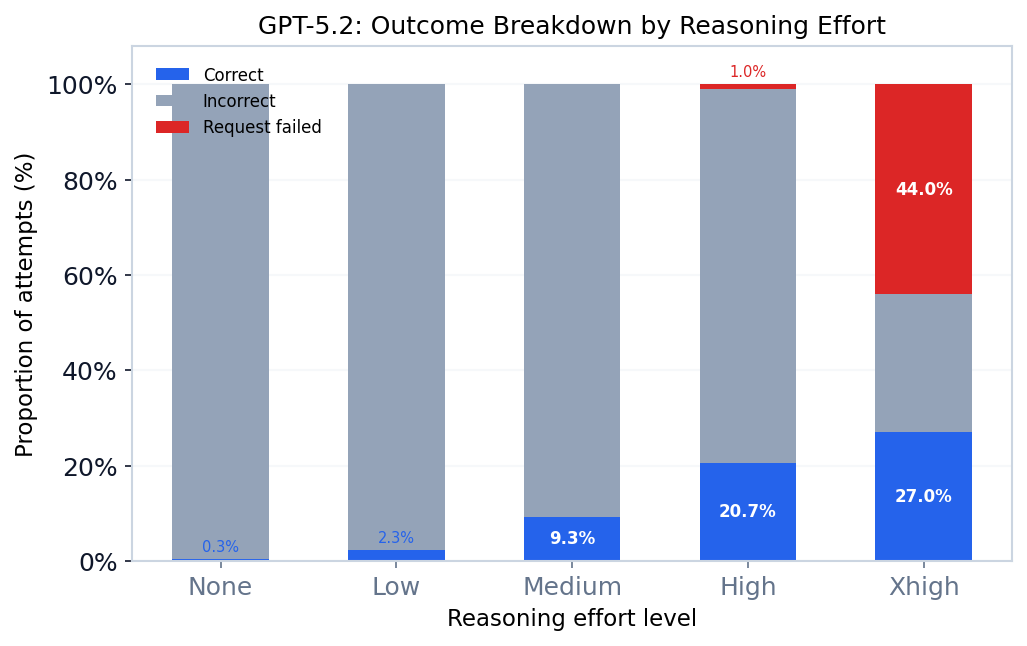
For GPT-5.2, increasing reasoning effort produces large gains in both direct and agentic settings — and also surfaces real-world constraints (timeouts / context limits) at the top end.
Agentic endurance: long-horizon reasoning
Agentic mode becomes a stress test for sustained reasoning:
- Median: 29 turns, 17 minutes
- P90: 113 turns
- Some attempts run for hundreds to 1,000+ turns across hours of wall-clock time
This is not a "one good chain-of-thought" benchmark. It's repeated decision-making + self-correction with deterministic feedback.
Cost: huge variance
Average cost per attempt: ~$1.66 across 17,032 runs.
Cost-per-success varies by ~67,000x across models. Many models are dominated by alternatives that are both cheaper and higher-performing — which makes Pencil Puzzle Bench useful not just as a scoreboard, but as a practical guide for "reasoning that actually scales."
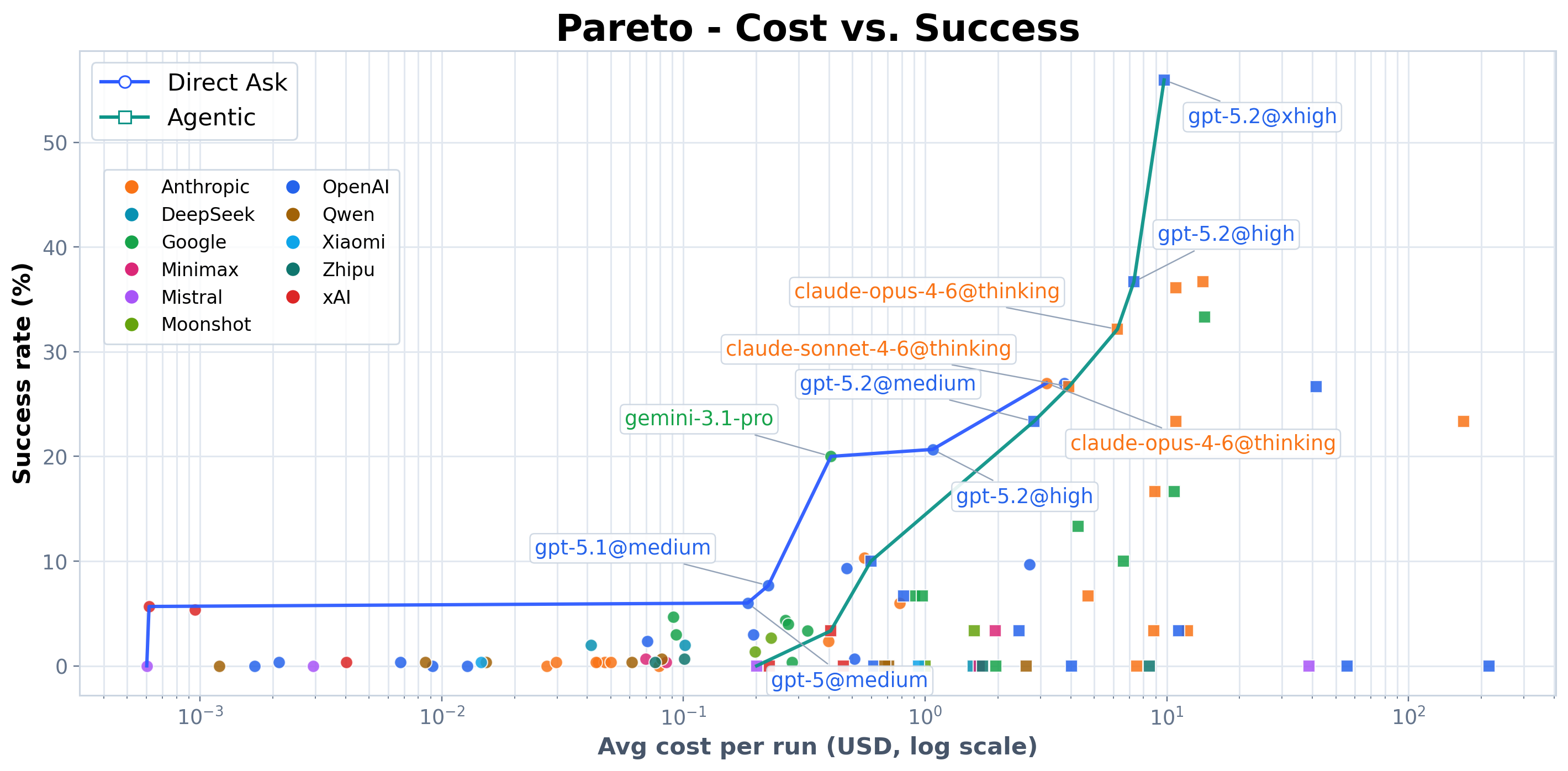
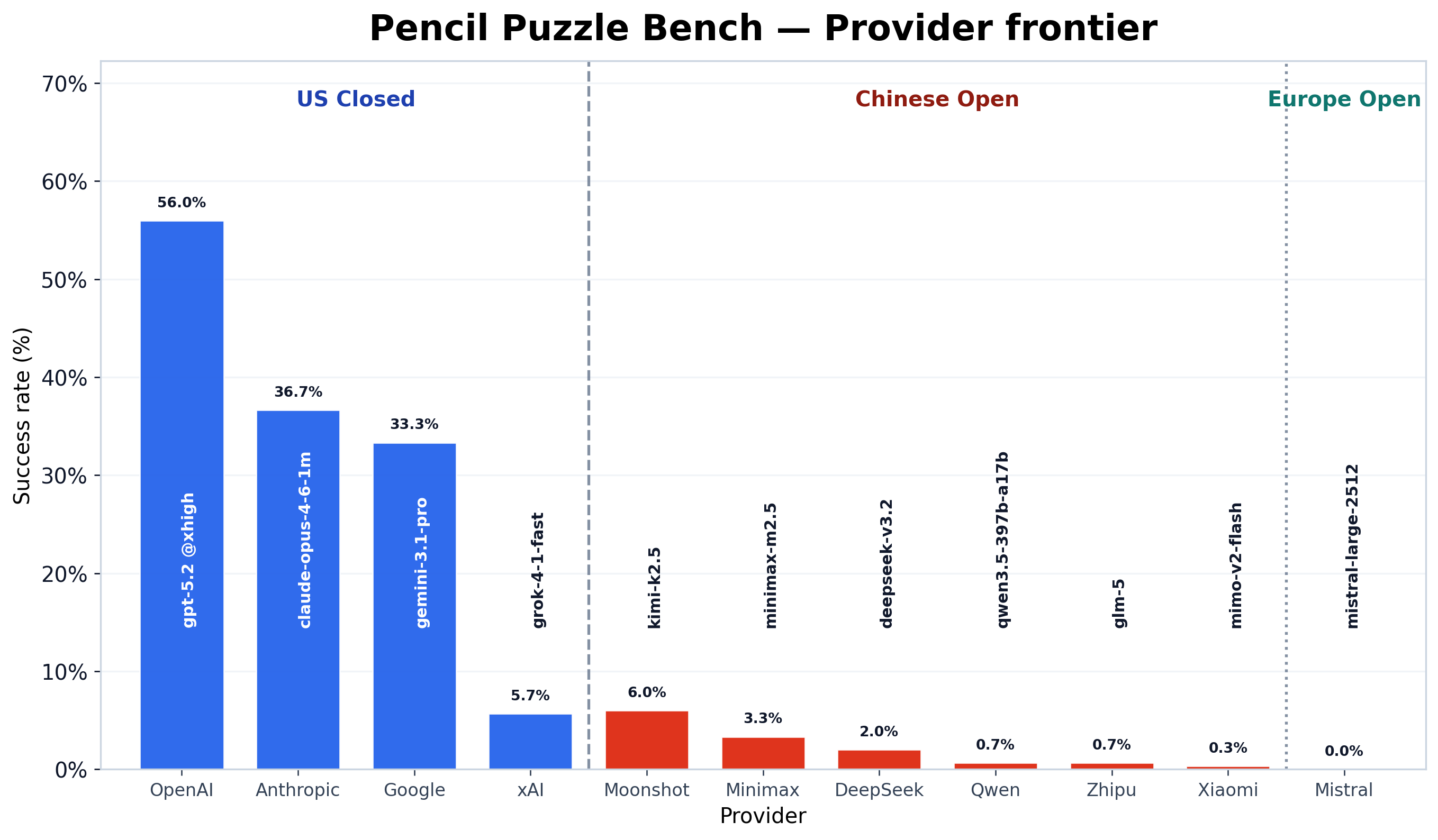
Provider frontier
Taking the best model from each provider, the gap between US closed-source labs and open-weight alternatives is stark. The top three providers (OpenAI, Anthropic, Google) all exceed 33%, while the best Chinese open-weight model reaches 6%.
Watch models solve puzzles
Every agentic solve attempt is recorded and can be replayed step-by-step on ppbench.com. Click any agentic model name in a puzzle's AI results table to watch the replay — you can see the model's reasoning, tool calls, resets, and the board updating move by move.
Here are three examples:
Claude Sonnet 4.5 solving a LITS puzzle — 214 tool calls, 62 resets before finding the solution.
GPT-5.2 (medium reasoning) solving a Light Up puzzle.
GPT-5.2 (xhigh reasoning) solving the same Light Up puzzle — fewer steps with more compute.
What's still unsolved
Even after agentic evaluation unlocks additional wins, about half of the benchmark puzzles remain unsolved by any model we tested.
That's the point: the benchmark is hard in a way that is cleanly measurable and useful for iteration.
Where we hope this gets used
If you're working on:
- process supervision / verifier-based training
- tool-using agents and error recovery
- long-horizon planning and memory under constraints
- RL from deterministic reward signals
... Pencil Puzzle Bench is built for you.
Resources
- Play the Puzzles: ppbench.com
- Paper: Paper (arXiv)
- Dataset + runs: Hugging Face
- Puzzle source: puzz.link